机器学习算法 --(5)决策树
一、概念和算法
1. 概念
比较适合分析离散数据,如果是连续数据要先转成离散数据再做分析。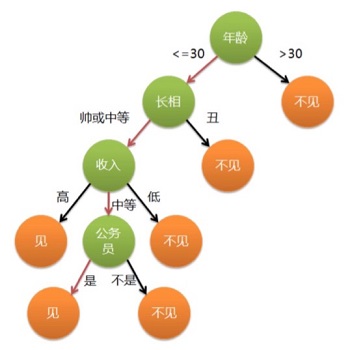
2. 算法
70 年代后期至 80 年代,Quinlan 开发了 ID3 算法。
Quinlan 改进了 ID3 算法,称为 C4.5 算法。
1984 年,多为统计学家提出了 CART 算法。
3. 熵
信息熵公式:$H [x] = -\sum_{x} {p (x) log_2 p (x)}$
4.ID3 算法
决策树会选择最大化信息增益来对节点进行划分。
信息增益计算:
$Info (D) = -\sum_{i=1}^m {p_i log_2 (p_i)}$
$Info_A (D) = \displaystyle \sum_{j=1}^v {|D_j| \over |D|} \times Info (D_j)$
$Gain (A) = Info (D) - Info_A (D)$
连续变量处理
可以分别对不同的划分点计算信息增益,选择使得信息增益比较大的划分点。
5.C4.5
信息增益的方法倾向于首先选择因子数较多的变量,因此可以使用信息增益的改进:增益率。
$SplitInfo_A (D) = - \displaystyle \sum_{j=1}^v {|D_j| \over |D|} \times log_2 {|D_j| \over |D|}$
$GrainRate (A) = \displaystyle {Grain (A) \over SplitInfo_A (D)}$
二、sklearn 实现决策树
重点:处理字符型数据1
2
3
4
5
6
7
8
9
10
11
12
13
14from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
# 创建决策树模型
model = tree.DecisionTreeClassifier (criterion='entropy')
# 输入数据建立模型
model.fit (x_data, y_data)
# 测试
x_test = x_data [0]
predict = model.predict (x_test.reshape (1,-1))
print ("predict:" + str (predict))
三、画出决策树
pip install graphviz
到 下载安装包,然后按照
设置环境变量 C:\Program Files (x86)\Graphhviz2.38\bin1
2
3
4
5
6
7
8
9
10
11
12import graphviz
dot_data = tree.export_graphviz (model,
out_file = None,
feature_names = vec.get_feature_names (),
class_names = lb.classes_,
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source (dot_data)
# 把这个图保存在当前的目录下
graph.render ('computer')
在决策树中剪枝是对抗过拟合的方法,方法是限制 “树的深度” 和 “内部节点再划分所需最小样本数”1
2
3
4# 创建决策树模型
# max_depth,树的深度
# min_samples_split 内部节点再划分所需最小样本数
model = tree.DecisionTreeClassifier (max_depth=7,min_samples_split=4)
机器学习算法系列
机器学习算法 —(1)线性回归和非线性回归
机器学习算法 —(2)逻辑回归
机器学习算法 —(3)神经网络
机器学习算法 —(4)KNN
机器学习算法 —(5)决策树
机器学习算法 —(6)集成学习
机器学习算法 —(7)贝叶斯算法
机器学习算法 —(8)聚类算法
机器学习算法 —(9)主成分分析 PCA
机器学习算法 —(10)支持向量机 SVM